In the first post, we took a look at the types of machine learning (ML) algorithms. The first one was supervised learning. When we think of the word, supervise, we guess that we’ll use data that is identified and separated properly (we know what result we get when we give specific input) to create a model. Some examples of supervised learning can be house prediction problems, understanding a handwritten text, and spam mail detection. There are various algorithms in supervised learning. But as the first thing in supervised learning, we’ll start with Linear Regression.
Linear Regression (LR) is a basic statistical method that applies a linear function to data and predicts a scalar value. A commonly used example of this method is predicting house prices.
Why do we use Linear Regression?
First, we want to predict in a better way by looking at the data and approaching it in a statistical way. Second, when there is a change in our feature, we want to know what the outcome will be. Lastly, to summarize the data. Instead of dealing with all the data, we want to create a linear function to define a correlation between feature and output.
As a simple example of a linear function, we’ll use the following equation:
(y = w * x + b)
Let’s split this equation into parts and check them one by one. w is called a weight/parameter. x is the input/feature, and b is the bias.
Parameters
Parameters are the values that control the behavior of the system. In machine learning, they are mostly called weights because the value of the parameters affects the system. So, an increase in the specific part of the weight vector increases the effect of that part on the prediction. And also, a decrease in a specific part of the weight vector decreases the effect of that part on the prediction. When the amount of the weight value is huge, it has a greater effect on the prediction. If it’s zero, there is no effect.
Inputs/Features
Inputs or generally called features in ML, are the values represented by x in our equation. Features are the direct affecting values in our function. For example, if we would like to predict house prices, our features can be the number of rooms, size of the house, and age. We’ll predict the price of a house by looking into those features with help from our parameters.
Bias
Bias is generally included in the definition of parameters. This is another value we would like to estimate. We can think of this value as the representation of our estimates when all features are equal to zero. In ML, we would like to learn weights and bias so-called parameters of our model (for now, linear regression function).
There are two types of Linear Regression, simple (univariate) and multiple (multivariate). We’ll define the general rules and strategy of linear regression, mainly under linear regression, for simplicity now. Then, we’ll focus on the multiple linear regression based on the learnings in here. In simple linear regression, we have only one feature. We can think the price of the house is only dependent on the size of the house. So, we only care about one feature. This is why it’s called simple.
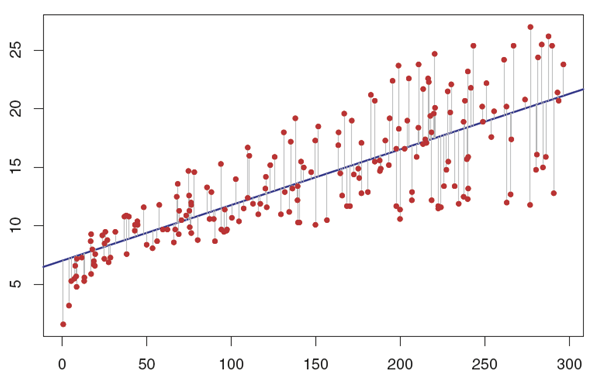
The red dots in the graph above represents our data set. Let’s guess some parameters and biases and draw our linear line into our data set like above. This seems like a pretty good guess when you think about the whole data. But we will have errors shown with gray vertical lines in the graph. Those errors are our cost of not being able to fit all the data. So, every approach will come with a cost, and we’ll measure our prediction’s performance according to the cost.
Cost/Error Function (measuring the performance)
As we said, we are using the cost function to measure the performance of the model. But how do we calculate the error in general? As stated in the graph as gray vertical lines, the difference between the actual value and the predicted value gives the error. By calculating the error, we can measure the accuracy of our prediction function. After finding the error, our main idea will change, and we’ll try to choose the parameter (w) and bias (b) values so that our cost will be minimum. Calculating the error comes from the simple mathematical approach; of calculating the distance between two points. Therefore, we’ll use mean squared error.
$$L(\hat{y}-y) = \frac{1}{m}\sum (\hat{y}-y)^2_i=\frac{1}{m}\left \| \hat{y}-y \right \|^2_2$$We can see in the formula that we subtract the actual value from the predicted value. And we take squares to get rid of negativity. Lastly, we take the average of our error in the whole of our data set. So, this measures the error. When the y^ and y are equal, the error will be 0. When the Euclidian distance between the predicted value and the actual value increases, the error increases as well.
Last Words
Now, we have our model (or hypothesis), and we have a way of measuring how well it fits into the data. Next, we need to estimate parameters w and b to decrease the cost. Machine learning and deep learning are based on minimizing the cost with different approaches. We hear the terms curve fitting and global minimum in the curve many times. It comes from the error function. As we saw above, the error function takes squares to get rid of negativity. So, if we try to draw the graph of the error function, it will be in a curve shape (in a simple linear regression case, parabolic). Finding the minimum point of a curve is the main idea.
Further: